itext 5.3.0 で UniJIS-UCS2-HW-H を指定した場合、欧文文字の幅がおかしい
itext 5.3.0がリリースされていたので試してみたところ、UniJIS-UCS2-HW-Hを指定した場合、欧文文字の幅が広がっていた。
5.1.3で出力した場合
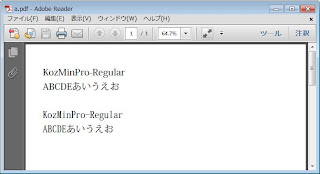
5.3.0で出力した場合

PDF出力に使用したサンプル
5.1.3の場合
5.3.0の場合
BaseFont#getCidCodeの値が異なっている。 itextのCJKFont.java の 170行目あたりを見てみると、 指定したエンコーディングではなく、 「cjk_registry.properties」のXXXXX_Uniの定義にあるエンコーディングを使用するようになっている。
HeiseiKakuGo-W5.properties
CJKFont.javaを改変し、「uniMap」変数に指定したエンコーディングを直接指定すれば、5.1.3と同じように出力できる。
5.1.3で出力した場合

5.3.0で出力した場合

PDF出力に使用したサンプル
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(filename));
document.open();
BaseFont bfH = BaseFont.createFont("KozMinPro-Regular",
"UniJIS-UCS2-H", BaseFont.NOT_EMBEDDED);
Font fontH = new Font(bfH, 20);
document.add(new Paragraph(bfH.getPostscriptFontName(), fontH));
document.add(new Paragraph("ABCDEあいうえお", fontH));
document.add(Chunk.NEWLINE);
CJKFont bfHW = new CJKFont("KozMinPro-Regular", "UniJIS-UCS2-HW-H",
BaseFont.NOT_EMBEDDED);
System.out.println("AのCID CODE:" + bfHW.getCidCode('A'));
Font fontHW = new Font(bfHW, 20);
document.add(new Paragraph(bfHW.getPostscriptFontName(), fontHW));
Paragraph p = new Paragraph("ABCDEあいうえお", fontHW);
document.add(p);
document.close();
System.out.println("done...." + RESULT);
コンソール出力は以下のとおり。
5.1.3の場合
AのCID CODE:264
done....results/a.pdf
done....results/a.pdf
5.3.0の場合
AのCID CODE:34
done....results/b.pdf
done....results/b.pdf
BaseFont#getCidCodeの値が異なっている。 itextのCJKFont.java の 170行目あたりを見てみると、 指定したエンコーディングではなく、 「cjk_registry.properties」のXXXXX_Uniの定義にあるエンコーディングを使用するようになっている。
private void loadCMaps() throws DocumentException {
try {
fontDesc = allFonts.get(fontName);
hMetrics = (IntHashtable)fontDesc.get("W");
vMetrics = (IntHashtable)fontDesc.get("W2");
String registry = (String)fontDesc.get("Registry");
uniMap = "";
for (String name : registryNames.get(registry + "_Uni")) { // <--------------------- Adobe_Japan1_Uni
uniMap = name; // <-------------- Adobe_Japan1_Uni=UniJIS-UTF16-H
if (name.endsWith("V") && vertical)
break;
if (!name.endsWith("V") && !vertical)
break;
}
if (cidDirect) {
cidUni = CMapCache.getCachedCMapCidUni(uniMap);
}
else {
uniCid = CMapCache.getCachedCMapUniCid(uniMap);
cidByte = CMapCache.getCachedCMapCidByte(CMap);
}
}
catch (Exception ex) {
throw new DocumentException(ex);
}
}
今回のサンプルロジックを実行した場合、「registryNames」変数は、「cjk_registry.properties」ファイルの、「fontDesc」変数は「HeiseiKakuGo-W5.properties」ファイルの情報を持っている。
それぞれのファイルの内容は以下のようになっている。
HeiseiKakuGo-W5.properties
Flags=4 FontBBox=[-92 -250 1010 922] .... Registry=Adobe_Japan1....cjk_registry.propertie
Adobe_Japan1=78-EUC-H 78-EUC-V ...UniJIS-UCS2-H UniJIS-UCS2-HW-H... ... Adobe_Japan1_Uni=UniJIS-UTF16-H UniJIS-UTF16-V結局のところ、「HeiseiKakuGo-W5」の「Registry」の値である「Adobe_Japan1」+「_Uni」で参照できるエンコーディング「UniJIS-UTF16-H」が「HeiseiKakuGo-W5」を使う場合には使用されてしまっていた。
CJKFont.javaを改変し、「uniMap」変数に指定したエンコーディングを直接指定すれば、5.1.3と同じように出力できる。
コメント
コメントを投稿